
· 6 min read
A False Recipe, a Real Image
grimoire

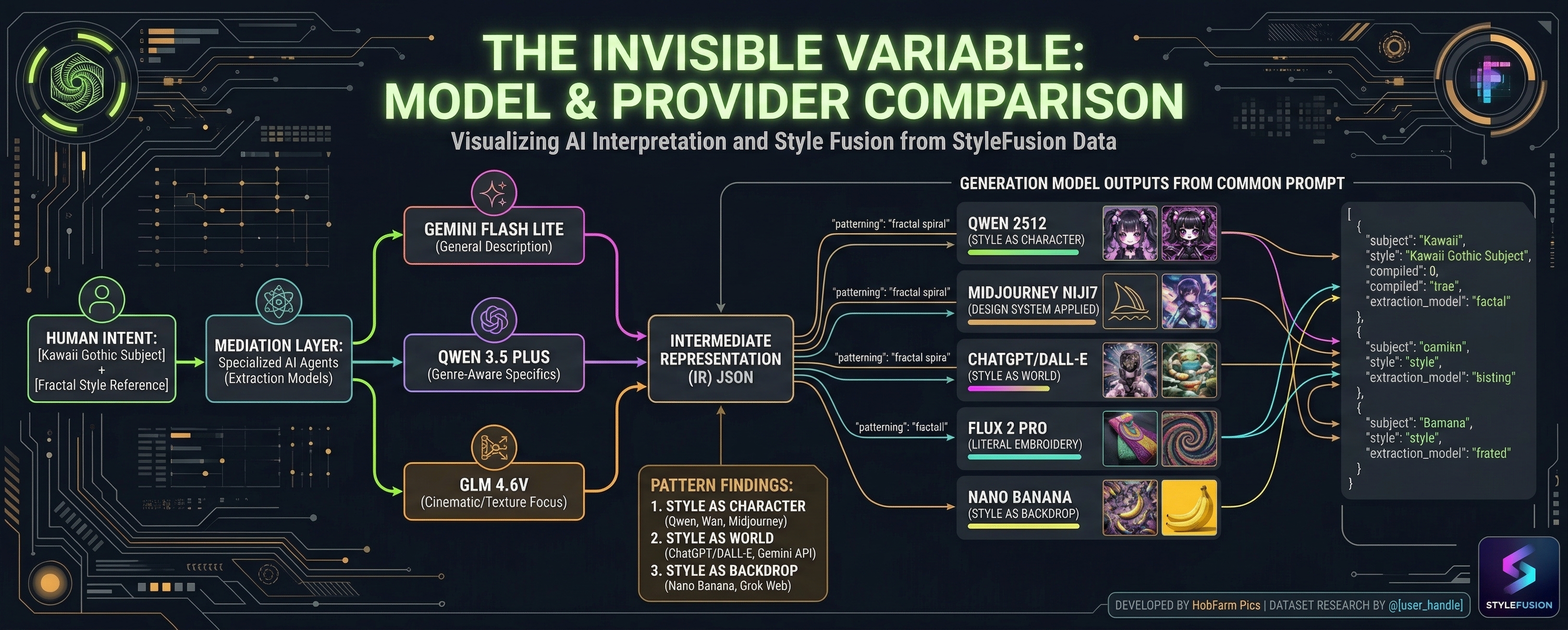
Five AI vision models extract structured metadata from the same reference images. The differences cascade through twelve generation endpoints. The extraction model is a creative director, not a passive observer.
There are three layers to AI image generation that most people collapse into one. The first is prompt engineering: writing text, sending it to an image model, tweaking words until the output improves. That’s what everyone talks about.
The second is vision interpretation: when you use a multimodal model to analyze a reference image, each model reads that image differently. Different vocabulary, different emphasis, different art-historical framing. Those differences cascade into the final output.
The third layer is the one nobody’s discussing at all: vocabulary reinforcement. If the words describing your image align with terminology the generation model saw thousands of times during training, the model renders with higher confidence. It’s the same principle as repeating a term in a prompt for emphasis, or weighting a token in Stable Diffusion. The model recognizes the vocabulary and commits to it.
Most people are optimizing layer one. I built a system that controls all three. Then I ran the test nobody else can run.
I wasn’t planning a research project. I was debugging.
I’d been building StyleFusion, an image generation platform that sits between human intent and AI execution, and during a routine update I noticed something I couldn’t explain. The same reference images, processed through different extraction models, were producing wildly different generation results even when everything else in the pipeline stayed the same.
That shouldn’t happen if extraction is just “describe what you see.” But extraction isn’t just description. It’s interpretation. And each model interprets differently.
I wrote about the initial finding and published it on Deviant Art, but the test was informal, run during a debug session with whatever was convenient. After finishing the updates I’d been working on, I wanted to do it again. Properly. With purpose. Five extraction models, twelve generation endpoints, three carefully chosen reference images, and the latest pipeline running clean.
This is what I found.
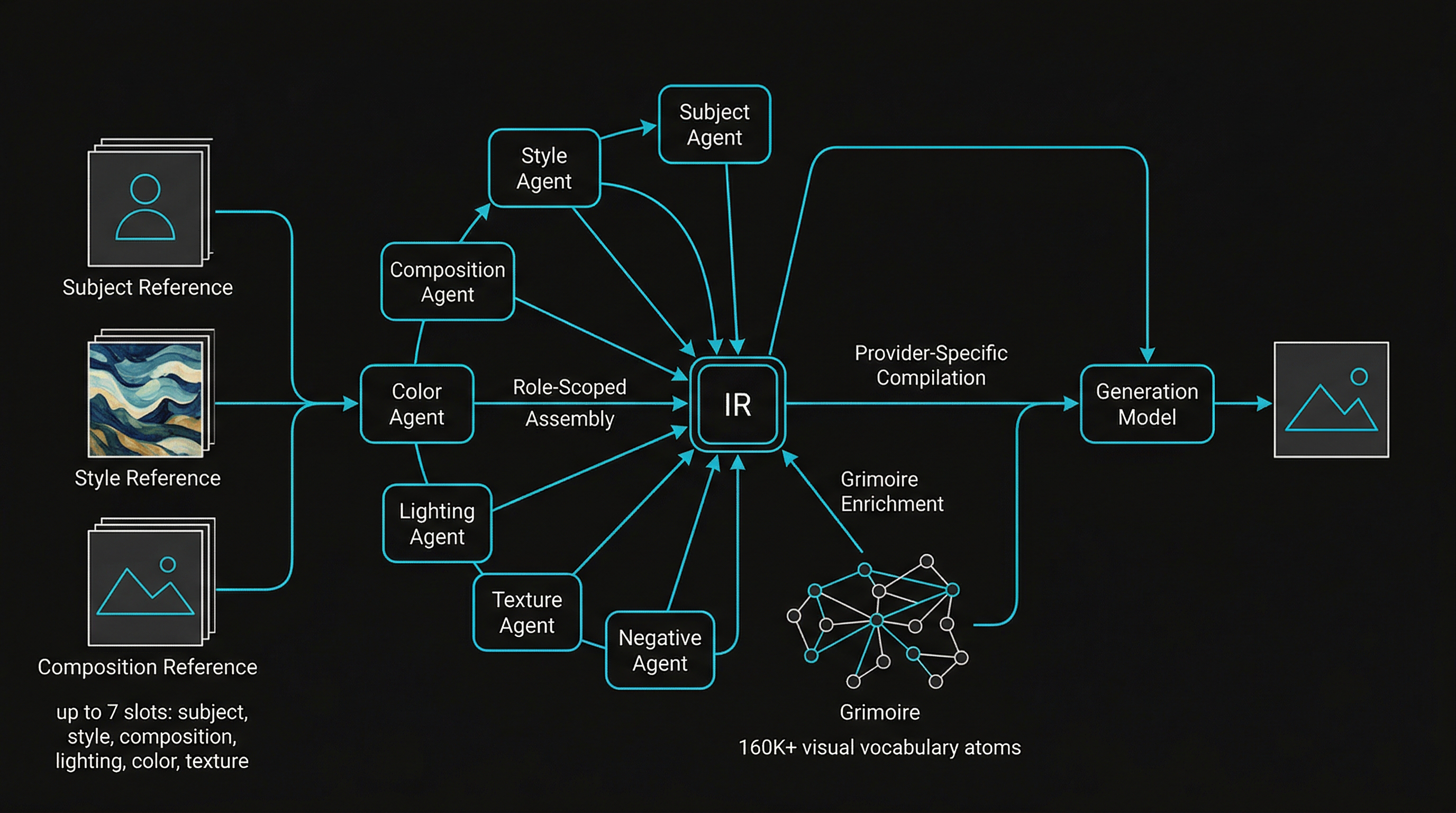
Instead of sending a text prompt to an image generator, StyleFusion runs a structured pipeline. You provide reference images and assign each one a role: subject, style, composition, lighting, color, texture. Seven specialized AI agents analyze each reference independently. One extracts the subject description, another identifies the style vocabulary, another maps the color palette, another reads the lighting, another handles texture, another handles composition, and another generates the negative prompt.
Their outputs feed into a role-scoped assembly that respects which image contributed what. The style reference’s scene elements don’t contaminate the subject’s environment. The composition reference’s visual appearance doesn’t override the style. A compilation step synthesizes everything into a structured Intermediate Representation, the IR, which is essentially a comprehensive JSON blueprint enriched by a knowledge graph I built called the Grimoire (160,000+ visual vocabulary terms (atoms) with numeric and harmonic dimension scoring), which was built as a result of me rediscovering an old A1111 folder with all my Dynamic Prompts wildcard text files.
The IR gets compiled into provider-specific prompts and sent to whatever generation model you choose.
Every step produces inspectable, diffable JSON. Nothing is a black box except the generation model itself. That transparency is what makes this study possible.
There’s a reinforcement effect happening between the Grimoire knowledge graph and the generation models’ training data. When the IR says “Art Nouveau flowing curves with iridescent chromatic aberration,” and the generation model has seen thousands of images captioned with exactly those terms during training, the model gets a double signal. The structured prompt says X, and the model’s own training says “yes, X is a real thing I know how to render.” The vocabulary alignment between the Grimoire and the model’s training data creates a confidence boost in the generation, similar to how duplicate reference images strengthen a concept.
This is why the IR produces better results than hand-written prompts. It’s not just more detailed. It’s more aligned with what the model already understands.
The practical upside: I’m not starting from blank prompts. I feed in images that are close but not quite right, let the extraction agents decompose them into swappable structured components, then recombine and route to different generators. The IR is a creative remix format, not just a description format.
Three reference images. Each assigned a different role. Each chosen to stress the pipeline in specific ways.

Subject: A 1920s theatrical performer in a butterfly costume. Sheer striped bodysuit, enormous sequin-trimmed wings, bobbed hair with wire antennae, arms outstretched. A photograph from roughly a century ago. The costume’s ambiguity is the test: is the butterfly part of her or worn by her? Models that understand costume-as-extension-of-body will render the wings differently from models that parse it as “woman standing in front of a prop.”
Style: A kaleidoscopic digital mandala of repeating peacock style eye motifs. Neon cyan, hot magenta, lime green against a deep void background. Radial symmetry with organic-geometric hybrid forms. The eyes are biological shapes rendered with mathematical precision. This is a maximally chromatic reference feeding into a monochrome subject. How each generation model resolves that tension (does the character stay desaturated? become fully chromatic? absorb color only in the wings?) is a clean discrimination axis.
Composition: A baroque-era optical diagram. Kircher-era perspective studies with construction lines, labeled figures, ray-tracing geometry on aged parchment. This asks something fundamentally different from the other two references: don’t just change how the character looks or what surrounds her, change the structural logic of the image itself. Render it like a figure in a technical treatise.
The intended output: a 1920s butterfly performer rendered in psychedelic mandala style, composed as though she were a plate in a scientific manuscript.
No human would write that prompt. The IR has to mediate it.
I ran these three references through five different extraction models, keeping everything else identical. Then I sent each IR to twelve generation endpoints. Same references, same pipeline, same compilation logic. The only variable was which model interpreted the images.
Each model produced a complete IR from the same three references. The structural format is identical. The content is not.
Style anchors: “computational art, fractal visualization, generative mathematics, mathematical aesthetics, digital symmetry, chaos theory art.”
Grok described the eye mandala using actual fractal mathematics vocabulary. Escape-time algorithms. Orbit traps. Flame fractals with IFS and log-density histogramming. Seahorse valleys. Mini-brots nested within larger structures. This model knows what fractal math is and describes the image in those terms. The subject was explicitly period-anchored as “a 1920s-era performer.” The scene was “a sterile, white technical workspace.”
The generation grid reflects this precision. Outputs are structural, restrained, architectural. Dark wings dominate. When color appears, it’s precise accent, not saturation flood. The composition reference (the Kircher diagram) got the strongest pickup of any extractor. Multiple outputs show lab environments, optical instruments, construction geometry. Grok told the generators “sterile technical workspace” and they believed it.
The outlier in the grid is a Bauhaus-influenced colorful panel where one generator interpreted “mathematical aesthetics” as constructivist design rather than digital fractal art. Different training data, different interpretation of the same vocabulary.

Style anchors: “psychedelic art, visionary fractal, kaleidoscope symmetry, digital surrealism.”
Where Grok filed a technical report, Qwen wrote a creative brief. The subject description is lyrical: “A slender woman stands transformed into a living butterfly… embodying enchanted metamorphosis… a silent moment of magical becoming.” That narrative framing gives generation models permission to be more expressive, and they took it.
The grid is the most saturated of the five. Neon everywhere. The mandala palette made it into the wings, the bodysuit, the environment, everything. Several outputs show the composition reference surviving as geometric diagram elements scattered around the figure. The standout is the center monochrome line-art butterfly panel: one generation model heard “technical diagram” louder than “neon fractal” and went full composition-reference, dropping the psychedelic style entirely. That’s a generation model making its own priority call from the same IR that produced neon explosions elsewhere in the grid.

Style anchors: “psychedelic art, visionary art, kaleidoscope symmetry, Art Nouveau influence, digital surrealism.”
Gemini was the only extractor to pull an Art Nouveau reference from the eye mandala. It saw the organic curves and flowing forms where others saw fractals or psychedelia. That single vocabulary choice cascaded through the grid: several outputs have that unmistakable Art Nouveau quality of sinuous, whiplash curves defining the forms.
This is also the widest-range grid. Same IR, and the outputs include vintage sepia, neon psychedelic, technical drawing, and earth-toned Art Nouveau. Gemini’s balanced extraction didn’t push hard in any single direction, which means the generation models had maximum interpretive latitude. What you’re seeing in the Gemini grid isn’t just Gemini’s personality. It’s every generation model’s default personality revealed by a neutral extraction.

Style anchors: “psychedelic art, kaleidoscope symmetry, Art Nouveau-inspired, 1960s psychedelic, psychedelic poster art.”
The “1960s” specificity is unique to GLM. No other extractor dated the psychedelic reference. Its descriptions throughout read like an art director giving a creative brief rather than an analyst filing a report. The generation grid reflects this: flat, graphic, designed-looking outputs. Several panels have the specific quality of concert poster art rather than 3D rendering. The striped bodysuit came through with high consistency.
The bottom-right panel is one of the strongest three-way fusions in the entire dataset (image model is Qwen Image 2512 from Fal.ai). An Art Nouveau fairy figure against aged parchment with geometric diagram elements. Subject preserved, style applied as illustrative design language, composition reference present as background texture and layout logic. All three references, all three integrated, none dominating. That’s what clean fusion looks like.


Style anchors: “psychedelic, visionary art, neo-psychedelia, ornamental symmetry, contemporary digital ornament.”
“Neo-psychedelia” and “contemporary digital ornament” are art-historical genre terms the other models didn’t reach for. GPT-5 Mini’s vocabulary is curated and precise. The subject description is efficient: “Oversized glitter-trimmed butterfly wings frame a slender woman in a ruched halter jumpsuit.” No poetry. Just accurate observation with carefully chosen words.
The grid is the most elegant of the five. Warm gold and champagne tones dominate. The vintage photograph feeling survived here where other extractors killed it. The others wrote aggressive negative prompts suppressing sepia, film grain, period qualities. GPT-5 Mini’s negative was gentler, and its subject description retained enough period vocabulary (“vintage showgirl presentation”) to anchor warm tones even when the style pushed toward neon.
The sketch panel went fully illustrative in a direction no other IR produced. One generation model took GPT-5 Mini’s restrained vocabulary and went full storybook. That interpretive freedom comes from the precision: when the IR doesn’t over-specify, the generator fills in its own aesthetic.

This is the finding that matters.
The extraction model doesn’t just describe what it sees. It makes aesthetic decisions. It chooses which vocabulary to use, which details to emphasize, which art-historical references to invoke. Those choices cascade through the entire pipeline and into the final image.
Grok’s mathematical vocabulary produces structural, architectural outputs. Qwen’s lyrical vocabulary produces expressive, saturated outputs. GPT-5 Mini’s curated vocabulary produces elegant, restrained outputs. GLM’s poster-art vocabulary produces flat, graphic, illustrative outputs. Gemini’s balanced vocabulary produces the widest range, letting each generation model show its own personality.
This isn’t a quality ranking. It’s a routing table.
When I want poster art, I route extraction through GLM. When I want elegant art deco period work, ChatGPT. When I want mathematical geometry, Grok. When I want broad general quality, Gemini. When I want tight style adherence, Qwen.
You learn this the same way you learn any creative material. Use them long enough and the patterns emerge. The same default smiles. The same eye placements. The same color tendencies. The same prompt patterns. Every model has a signature, every computer system has a pattern. Once you see the signature, you stop wasting time on things that don’t work well and start building on things that do. That’s the actual skill curve of working with generative AI: material knowledge. Not prompt engineering. Material knowledge.
I first noticed this about three years ago when Midjourney released the /describe feature. You’d feed it an image and it would tell you what it saw, essentially reverse-engineering its own prompt language. The output always followed the same structure: subject, in the style of, compositional elements, color, lighting and camera, texture. That decomposition wasn’t arbitrary. It was Midjourney revealing how its model organized visual information internally. The terms it chose were the terms it had been trained on: weirdcore, cottagecore, nintencore, mommy’s-on-the-phonecore. An entire taxonomy of aesthetic vocabulary that existed because those were the captions attached to the training images.

That was the moment it clicked. The model wasn’t being creative with those terms. It was pattern-matching against its own training data. If you used the exact vocabulary the model had learned from, you got stronger results. Not because the words were better descriptions of what you wanted, but because they mapped directly to visual patterns the model had already internalized. The words were keys that unlocked specific rendering behaviors.
StyleFusion’s seven extraction agents follow essentially the same decomposition that Midjourney’s /describe surfaced naturally: subject, style, composition, color, lighting, texture, negative. The IR formalizes what /describe revealed informally. And the Grimoire takes it further: instead of hoping you stumble onto the right vocabulary, it systematically matches visual concepts against 160,000+ terms organized by harmonic dimensions, so the prompts speak each generation model’s native language by design rather than by luck.
The IR makes that material knowledge visible and systematic instead of anecdotal. Without the structured intermediary, you accumulate gut feelings about “Midjourney does X well” and “ChatGPT tends to Y.” With it, you can see exactly what each model received and what it did with that information. The intuition becomes data.
The negative prompt is as important as everything else in the IR, and it’s the one most people skip or treat as an afterthought. The way it works in diffusion models: during generation, the model is computing two predictions simultaneously. One steered toward your positive prompt, one steered toward the negative. The final output is pushed away from the negative and toward the positive. So when the IR’s negative says “avoid sepia-toned film grain, period-accurate costume textures, matte paper surfaces,” it’s not just a list of don’ts. It’s actively narrowing the probability space. The model has less to choose from, which means it commits harder to what’s left.
Think of it like a sculptor removing material. Every concept you exclude makes the remaining concepts more defined. This is also why the five extraction models’ negative prompts matter as much as their style anchors. GPT-5 Mini wrote a gentle negative that let the vintage warmth survive. The other four wrote aggressive negatives that killed period qualities entirely. That single difference in what each model decided to suppress is why the ChatGPT grid looks warm and the Qwen grid looks neon. The negative prompt shaped the output as much as the style description did, just from the opposite direction.
The third reference was the hardest test. Subject and style are standard two-input fusion. The composition reference asks something structurally different: adopt the spatial logic of an 18th-century technical diagram.
It survived at different rates across extractors, and the rates map directly to how specifically each model described the scene.
Grok described it as “a sterile, white technical workspace filled with various geometric diagrams and experimental apparatuses.” Clinical, specific, spatial. Generation models responded with actual lab instruments, construction geometry, diagrammatic layouts.
Qwen described it as “a flat, technical workspace depicted on a parchment surface.” Softer, less specific. Generation models scattered geometric elements in backgrounds but didn’t commit to the diagrammatic layout.
GPT-5 Mini produced the weakest composition pickup, mostly reducing the diagram reference to aged paper texture and warm tones.
The lesson is straightforward. Specificity in the IR’s scene description directly controls how much the composition reference influences the output. Vague descriptions get ignored. Precise ones get rendered. The extraction model’s vocabulary density for composition determines whether the third reference is a structural instruction or background noise.
Running this study means roughly 60 individual API calls per full pass. Five extractors, twelve generation endpoints. In practice, about a third of those fail, time out, or get content-filtered on first attempt. If you’re building production pipelines on top of these APIs, reliability matters as much as output quality.
The providers I can actually depend on: Gemini and Nano Banana 2 are the most solid. Almost always up, almost always fast. Grok is right there with them through the API. Qwen works every time on both fal.ai and the Alibaba Cloud endpoint, which is impressive for a model most Western developers haven’t tried yet. These are the ones you can build real workflows around without babysitting.
The rest require patience. FLUX 2 from Black Forest Labs is inconsistent on both fal and their direct endpoint. Sometimes fast, sometimes slow, sometimes just gone. And FLUX.2 flex on fal is probably the worst offender for false positive content filtering in this entire study. GLM is a frustrating split: the 4.6V vision model I use for extraction is excellent (sometimes slow, but it always works), while the image generation side is the least reliable endpoint in my pipeline. CogView-4 functions but produces weaker output quality compared to GLM-Image. ChatGPT is a different kind of unreliable: the model itself is capable, but content filtering behaves differently between the app, the web interface, and the API, which makes it unpredictable in automated workflows.
The censorship problem deserves direct comment. The subject reference is a public domain photograph from approximately 1920. A performer in a theatrical butterfly costume. Nothing remotely provocative by any reasonable standard.
Two providers refused to generate from IRs extracted from this image. The structured IR concentrates physical descriptors (sheer bodysuit, form-fitting, skin visible through fabric) that a hand-written prompt would scatter across natural language. A human typing “butterfly costume lady” passes every filter. A forensic JSON description of what the photograph actually contains gets flagged. The IR’s precision works against it because safety classifiers pattern-match on descriptor density rather than content intent.
The most revealing case: ChatGPT refused the Qwen-extracted IR in the app, then accepted the exact same content as JSON on their website and produced one of the strongest images in the entire study.

I needed a header image for this article. I gave Grok an early draft of the text and some IR exports from the tests, then asked it to create a banner. Then I ran the same prompt through Gemini. Each model received an IR that had been extracted by its own vision model from a previous generation, so Grok was working from Grok-extracted data and Gemini from Gemini-extracted data.

Gemini built an infographic. Flowchart with labeled nodes, connection lines, sample outputs, JSON snippets. It understood the prompt as “explain this system visually.”
Grok built branding. Dark surfaces, purple and cyan accent, circuit-board textures. It understood the prompt as “establish visual identity for this study.”
Same input, same intent, different interpretation. But the model isn’t the only variable here. Both Grok and Gemini have different custom instructions in my setup, different system prompts that shape their objectives and priorities. Grok’s instructions lean toward aesthetic identity and visual design. Gemini’s lean toward structured explanation and information architecture. So what you’re seeing is the combination of each model’s natural tendencies amplified by the role I’ve assigned it.
That’s another layer of the same finding: the context a model operates within shapes its output as much as the content it receives. The extraction-model-as-creative-director principle applies to every stage of the pipeline, not just the IR.
The conventional way to compare AI image generators is to send the same hand-written prompt to each one. That tests generation models. It doesn’t test the interaction between how visual concepts get described and how those descriptions get interpreted. That interaction is where most of the creative variance lives.
The generation model is the last mile. Everything before it determines whether that last mile produces coherent fusion or a confused mess. And “everything before it” is what StyleFusion exists to control.
Nobody else has this instrumentation, as far as I can tell. Most comparisons change multiple variables simultaneously and can never isolate which one caused which change. The IR makes every piece of the pipeline independently swappable and inspectable. The extraction model, the role-scoped assembly, the knowledge graph enrichment, the compilation format, and the generation model are all discrete variables in a controlled experiment.
The question isn’t “which AI image generator is best.” The question is “which combination of extraction vocabulary, prompt structure, and generation model produces the result you actually want.” The only way to answer that is to have a structured mediation layer that lets you test each variable independently.
That’s what I built. These are the results. The data is open, the IRs are published, and the methodology is reproducible by anyone who builds the same kind of intermediary layer. Or you could just use mine.
StyleFusion is live at sf.hob.farm. Built on Cloudflare Workers, AI Gateway, and D1. The Grimoire powers the vocabulary enrichment. HobFarm builds the invisible labor. The results speak for themselves.
Originally published as an X Article on March 19, 2026.


